The setup was super quick and easy. Once that was done, I decided to give it some time before I did an in-depth analysis of the tool. The product gives you a notification that the system may take some time to train all the models and learn how your data architecture works.
I surprised at just how hands off it was. I did all the connections and it worked as expected.
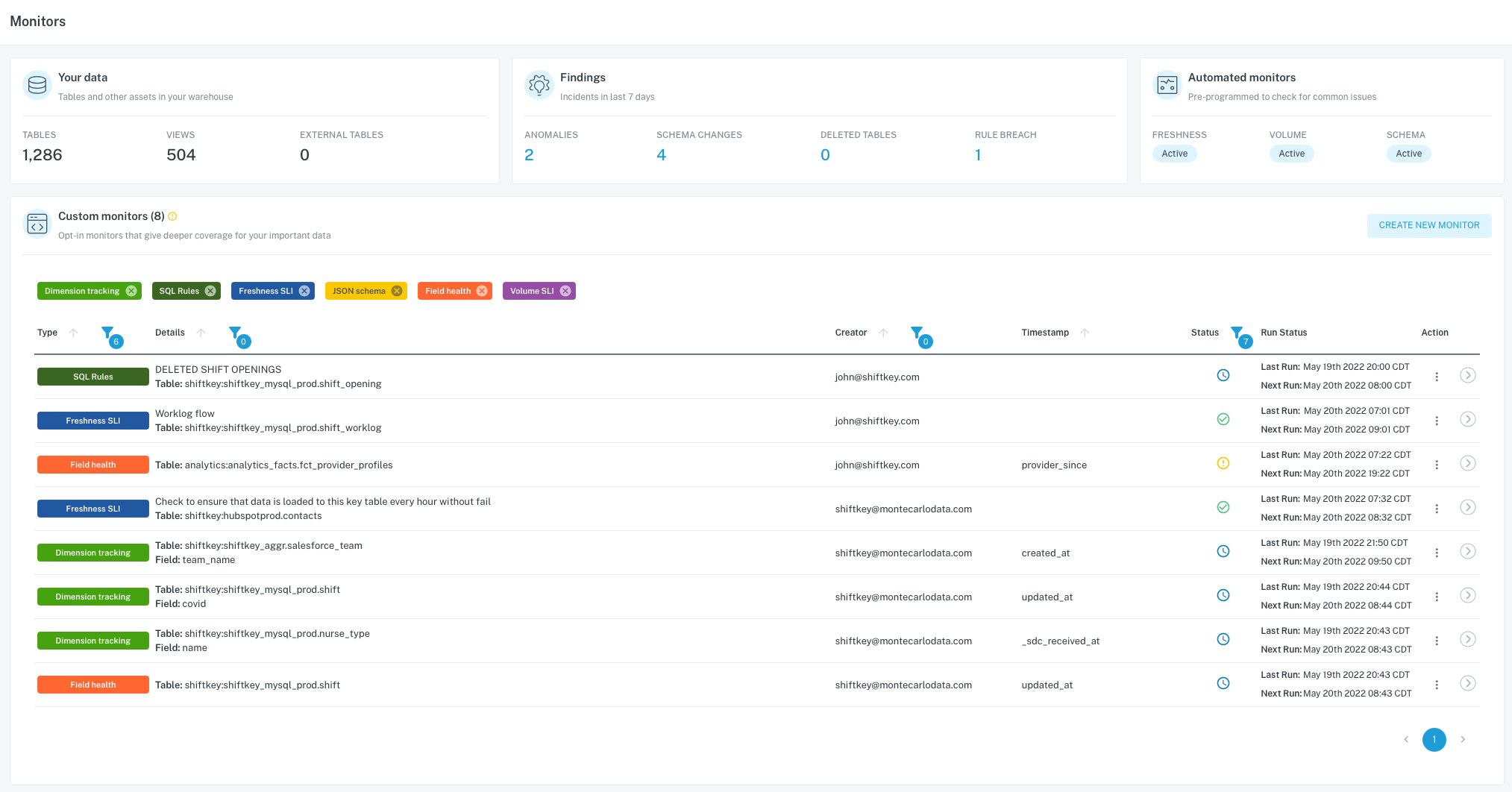
Dashboard
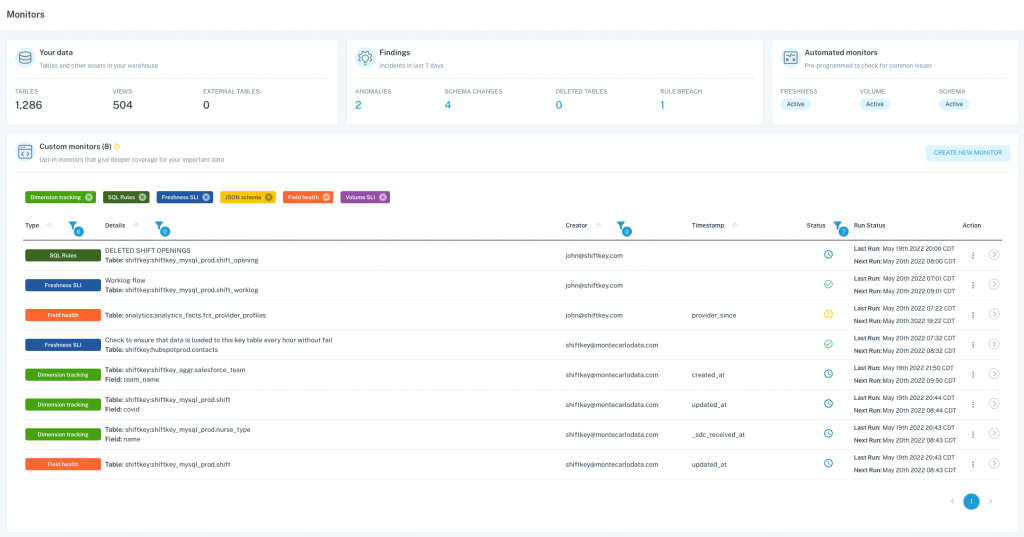
I’m not going to go into all the details but my high level review of the dashboard is that its organized in a way that I like. The dashboard is set up the way an engineering leader, qa or architect would need to see the data. Its not too much information that overwhelms you. Specifically there are a couple of pieces that stand out.
Findings
The findings area really stood out to me and it didn’t take me long to understand what the classification were.
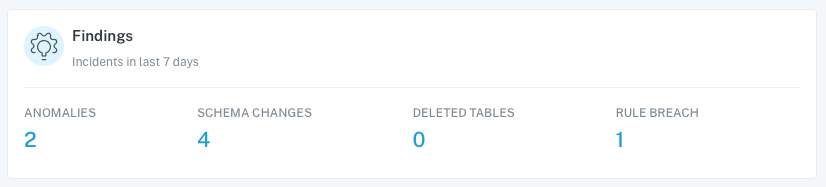
I was really curious to see the anomalies and rule breaches. For us on the data side, the schema changes are critical to staying ahead of potential downtime. These four we knew about because, here at Shiftkey, we have good communication with our engineering team.
Clicking in to those, you get the details of each incident the Monte Carlo software detects.
Automated Monitors
These were something I was excited to see. The freshness and volume items are something that we are so reliant on.
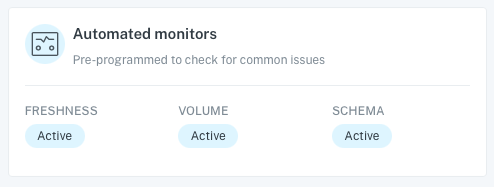
Now we have a way to understand if our data is being updated and flowing the way it should be. Unfortunately, I haven’t been able to see any notifications in this area yet. Probably because we have a good pipeline and service but im anxious to see this in action. We might simulate something in the next week to see it pick that up.
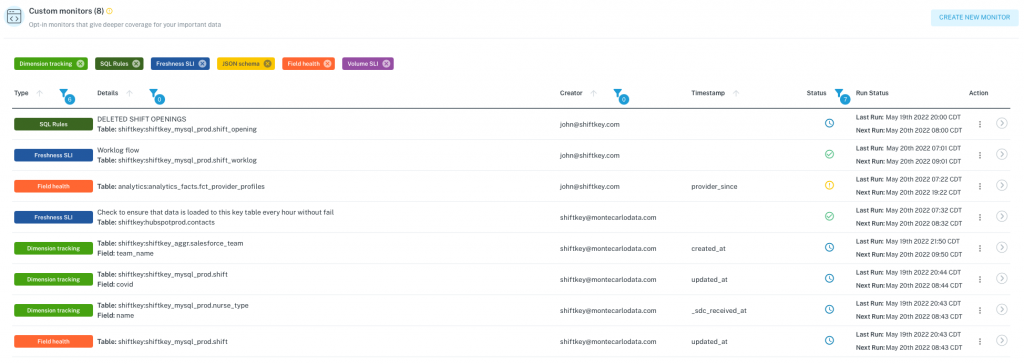
Custom Monitors
The Monte Carlo team set up a few to show off the platform but I was able to go in and start playing with some of the rules and it was pretty easy to learn how to set one up. I especially like the SQL monitors since I know our data and I can write scripts that should return expected results. But beyond that, the system rules seem pretty good. The training AI seems to do a good job of understanding the expected behavior.
Summary
Very good first impression. Provides a valuable suite of information in a very easy to use interface. I do anticipate more features and functionality in the future. There is a ton of personalization opportunity in the platform.
Next up, I am going to look at the catalog and pipelines areas. These are huge for us. (Understanding upstream/downstream dependencies).