You can expand your apis with suggested information the user might not know. Knowledge graphs are the key.
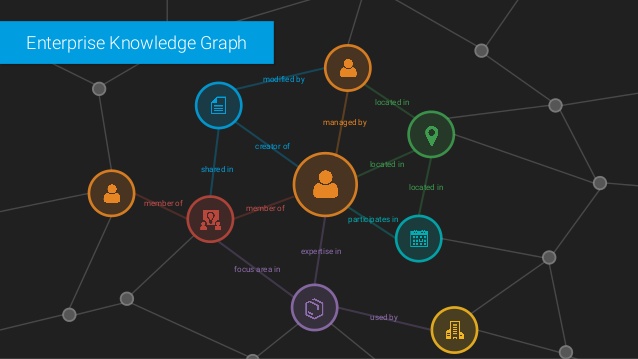
Expanding APIs with Knowledge Graphs
-
- 2 min
I was thinking this week about building services for headless applications and I thought, how can you differentiate these services from others which provide the known data of a system? Then I started to consider all the things I have done over the years in search and more specifically, advanced suggestion search. It occurred to me to provide additional information related to API returns within the same structure.
For example, say I am building an API to pull content from an existing database. I could easily just write the service to query for the exact response based on the contract (ask a question in a specific format, get an answer in expected format). But what if there was additional related content the requester might now know about? Something as simple as additional 3rd party links or as complex as 3rd or 4th degree relationships to additional consumer generated content (reviews, social posts, etc).
How does this work?
Knowledge graphs, for simplicity sake, are the common connections between data points that allow you to draw inferred relationships. For TV and movies, this could be actors, movies, directors, genres or locations. Its the way Netflix can take the movies you watch and suggest similar movies/genres you might like. It is also the way you search on google and the card on the right, interestingly enough known as the knowledge graph card, shows you more specific info on your search.
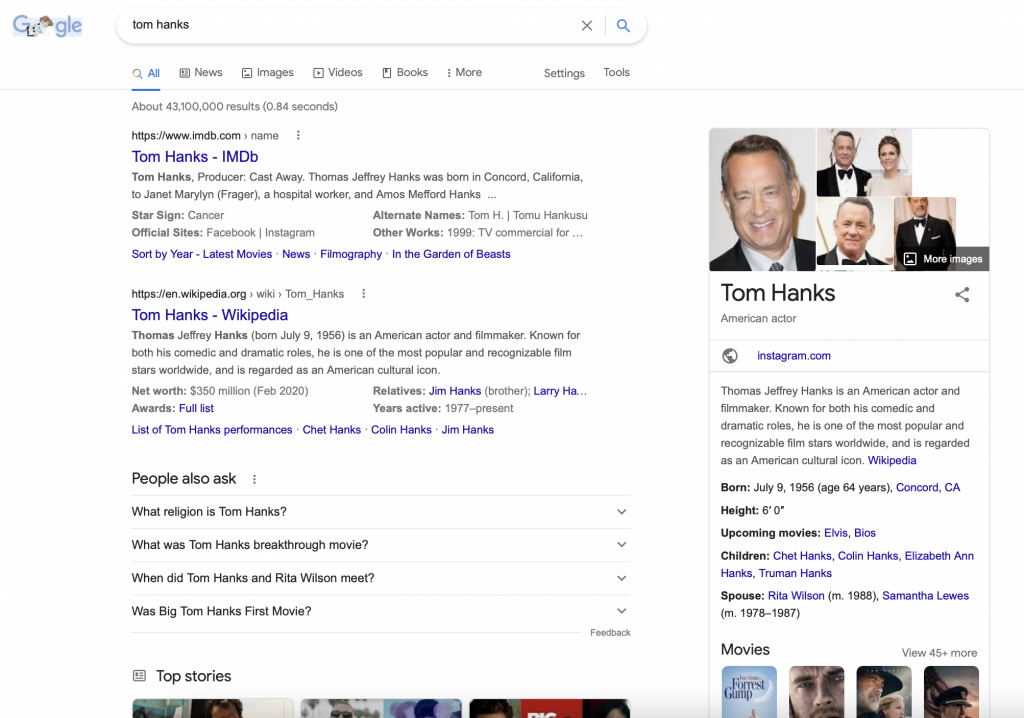
All that info to the right is generated dynamically from information found online about Tom Hanks. This is all based on relationship links in information sets found on the internet.
I love this article that explains knowledge graphs in more detail.
Also, the image they share is a great explanation of how the relationships are defined.
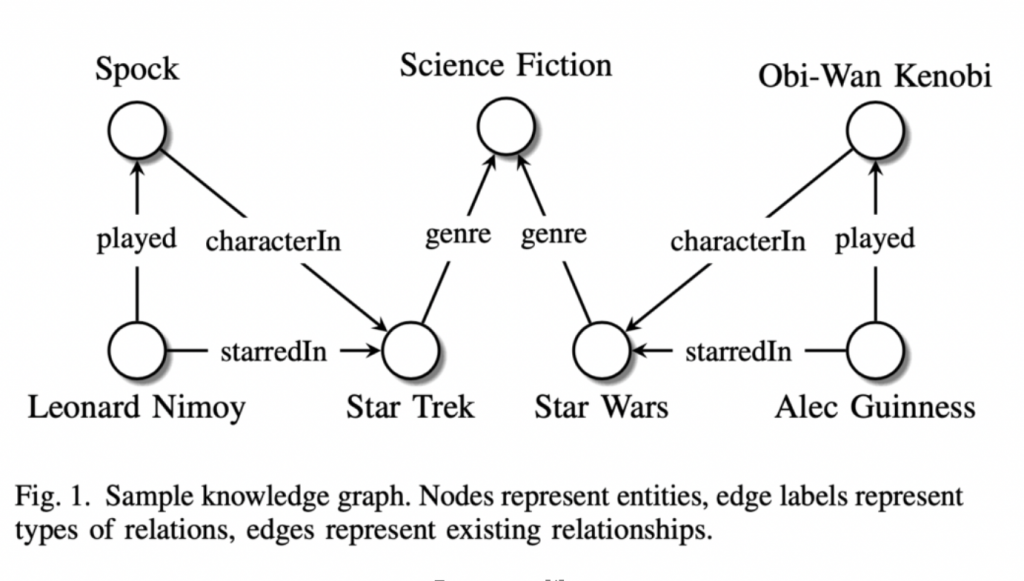
Indexing & Relationships
In order to make this work, you need to reprocess your data and create data indexes that highlight these individual relationships. If you don’t have those relationships defined, you can’t suggest anything. In addition to the individual terms or phrases, you could also do a more intensive content index of words and create more complex algorithms based on patterns, topics and frequency. There are so many applications for this type of technology.
Practical Applications
I love the search application of this for any industry. Medical (correlations, co-morbidities), insurance (correlations, risk pools) , finance (transactions), consumer (content, social) and more. It is crazy how little apps and sites don’t leverage even the simplest suggestion engines.
So, if you are building out services that give factual information via services, enhance those services with recommendations of additional value. This is just a teaser of more specific applications of this technology.